SOCの業務を支える代表的な技術とポイントも紹介
サイバー攻撃が高度化し、クラウド環境の利用が拡大するなかで「SOC(Security Operation Center)」への注目が高まっています。セキュリティ体制の見直しを進めたい企業にとって、SOCの役割や業務範囲を正しく理解することは、インシデントの早期発見・迅速対応を実現するうえで重要です。
本記事では、SOCの概要から必要とされる背景、担う業務、活用される技術、構築のステップまでを体系的に解説します。自社のセキュリティ監視体制をどのように整えるべきか、その指針となる情報を整理しましたので、参考にしてください。

目次
1. SOCとは
SOC(Security Operation Center)とは、企業のシステムやクラウド環境で発生するログ・アラートを常時監視し、サイバー攻撃の兆候を早期に検知するための専門組織です。
ログ監視から初動対応までを継続的に実施し、システム全体のセキュリティ状態を維持する中心的な機能を果たします。サイバー攻撃のスピードが上がり、気づいたときには社内の環境が侵害されているケースが増えるなか、SOCは異常の発見と被害拡大の防止を担う役割として重要性が高まっています。
CSIRTとの違い
CSIRT(Computer Security Incident Response Team)とは、重大なセキュリティインシデントが発生した際に、対応方針の決定や関係部署との調整、再発防止策の策定など組織としての対応を担うチームです。
一方のSOCは、インシデントが起こる前段階、つまり監視・検知・初動対応が主な役割であり、リアルタイムでログ分析やアラート判断を行う現場寄りの運用組織です。
両者は補完関係にあり、SOCは日々の監視と初動、CSIRTは重大インシデント時の意思決定と全社調整という役割分担で企業のセキュリティ体制を支えています。
MDRとの違い
MDR(Managed Detection and Response)とは、外部の専門ベンダーが提供する監視・検知・対応支援をまとめて提供するサービスです。24時間体制でアラート監視や分析を行い、必要に応じて初動対応のアドバイスや支援をしてくれます。
つまりMDRは、SOCの機能を外部へアウトソーシングするサービスです。自社での体制構築や人材確保が難しい企業において、MDRを活用してSOC機能を実装するケースが増えています。
2. SOCが必要とされる理由
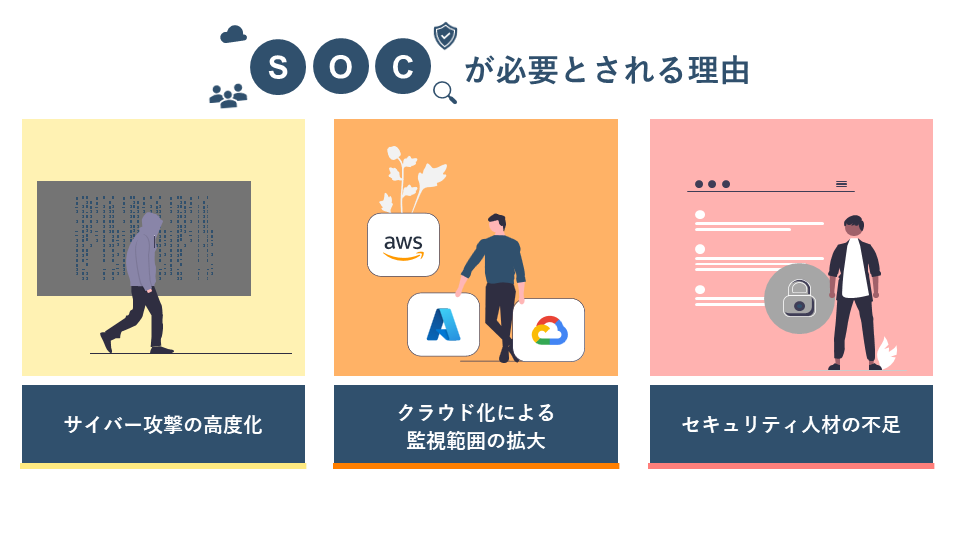
SOCが必要とされる背景を、3つの観点から整理します。
サイバー攻撃の高度化
マルウェアやランサムウェアは拡散が速く、攻撃のステップも巧妙化しています。実際に重大インシデントの平均ダウンタイムコストは74万円/分、累積コストは52億円/年に達するという調査結果もあり、一度の侵害が事業へ与える影響は無視できないものです。
また、令和6年と比較して、令和7年に1,000万円以上の復旧費用を要した企業は50%から59%へ増加しており、被害の高額化が進んでいることがわかります。
さらに、復旧期間が長引くほど損失額も大きくなる傾向があり、復旧に2か月以上を要した企業では1,000万円以上の被害割合が100%に達しました。
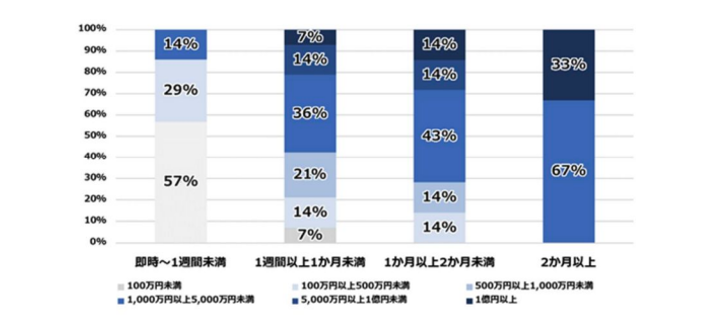
出典:令和7年上半期におけるサイバー空間をめぐる脅威の情勢等について(p8)
「気づいたときにはすでに侵害されていた」というケースが多く、膨大なログを目視で追う従来の方法では初動が間に合いません。そのため、24時間体制での継続的な監視やアラートの即時分析、迅速な封じ込めといった運用を常に回す必要があり、SOCの専門的な運用体制が求められています。
参考:
インシデントの平均修復時間6時間12分、システムダウンタイムのコストは1時間4,440万円。自動化で対応エンジニアの負担軽減へ。|インシデント管理プラットフォーム│PagerDuty
令和7年上半期におけるサイバー空間をめぐる脅威の情勢等について|警察庁Webサイト
クラウド化による監視範囲の拡大
クラウド環境では、監視対象がサーバーだけではなく、ネットワークやAPI、IAM、SaaS、コンテナなどに広がります。構成変更も日常的に発生し、ログの種類や量も急増しています。
そのため、担当者の目視では全体を把握しきれない問題が顕在化しているのです。さらに、設定不備や権限過多など、クラウド特有のミスが攻撃の入口になりやすく、継続的な検出と改善が欠かせません。
こうした環境変化に対応するには、多様なログを統合し、相関的に判断できるSOCのような監視基盤が必要です。
関連記事:AWS環境に必要なセキュリティ対策とは?考え方から具体的なサービスまで
セキュリティ人材の不足
ログ分析や相関分析、脆弱性管理、インシデント対応といった専門スキルを持つ人材は市場全体で不足しています。特に中堅規模の企業では、情シス部門が運用や開発を兼任するケースが多く、アラート分析が後回しになり、初動対応の遅れや対応漏れが発生しやすい状況です。
こうした背景から、常時監視と専門的な分析を行うSOCの体制が求められています。
3. SOCが担う主な業務
ここでは、SOCが実際にどのような業務を行うのかを解説します。
24時間体制の監視とアラート検知
SOCの中心となる業務は、システム全体のログやアクティビティを常時監視し、不審な操作や異常な挙動を早期に検知することです。夜間・休日を含めて状態を把握し続けることで、微細な変化や、通常と異なるアクセス・動作を迅速に検知します。
攻撃の多くは短時間で状況が変化するため、こうした24時間の継続監視が重大インシデントの防止につながります。
アラートの分析・トリアージ(重要度判断)
検知されたアラートはすべてが危険ではなく、誤検知や軽微なものも多いです。SOCでは、アラートの内容を精査し、どれが本当に対応すべき事象なのかを判断します。
具体的には、攻撃の入口や目的、想定される影響範囲を読み取り、「High/Medium/Low」といった優先度をつけることで対応の抜け漏れを防ぎます。また、判断が属人化しないよう、分析の基準やルールを整備し、誰が対応しても一定の品質でトリアージできるようにします。
インシデント管理・初動対応
アラートのなかでも重要度が高いものについては、初動対応を行い、被害の拡大を防ぎます。具体的には、アカウントの一時停止や通信の遮断、アクセス権の調整といった封じ込めの措置が中心です。
また、インシデントの状況や影響範囲を関係者へ共有し、対応が組織全体として統一されるよう調整します。初動対応後は原因の洗い出しや再発防止策の検討まで行うことで、継続的なセキュリティレベルの向上につなげます。
監視体制の維持と改善
SOCの業務はインシデント対応だけではなく、監視の精度を維持・改善するための継続的な運用も含みます。例えば、アラートルールの調整や監視項目の見直しを行い、過剰なアラートの発生を抑えつつ、必要なものを確実に検知できるようにします。
クラウド構成やシステム環境は頻繁に変わるため、それらに合わせて監視の内容を随時アップデートすることも欠かせません。また、月次レポートなどで運用状況をまとめ、改善点を整理することで、監査対応や証跡管理にも活用できる体制を維持します。
4. SOCを強化する技術
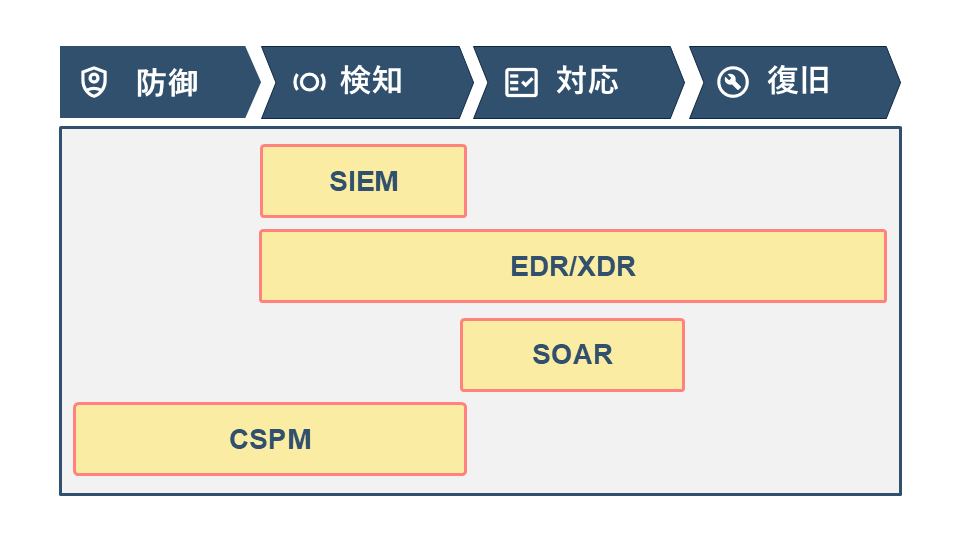
SOCの業務を支える代表的な技術を紹介します。
SIEM(ログの一元管理と相関分析)
SIEM(Security Information and Event Management)は、サーバー、ネットワーク、クラウド、アプリケーションなど多様なログを集約し、攻撃の流れを可視化するための基盤となる技術です。
個々のシステムでバラバラに発生するアラートを相関づけることで「どこから侵入し、どのように動いたのか」といった全体像を把握しやすくなります。SOCの分析やトリアージの精度を高める中心的な役割を担っており、増え続けるログを効率良く扱うためには欠かせません。
EDR/XDR(エンドポイント監視と攻撃の横断的検知)
EDR(Endpoint Detection and Response)は、端末やサーバー上で発生する挙動をリアルタイムに監視し、侵入後の不審な動作を検知する技術です。
XDR(Extended Detection and Response)は、エンドポイントに加えてネットワークやクラウドのログも横断的に分析し、攻撃の全体像をとらえやすくします。
攻撃者は一度侵入すると、別の端末やサーバーへアクセス範囲を広げようとします。EDRはこうした端末上の異常な操作を検出でき、XDRは複数のシステムにまたがる動きをまとめて把握しやすいことが特徴です。
これにより、インシデントの原因や影響範囲を迅速に特定できるようになります。
SOAR(対応の自動化)
SOAR(Security Orchestration, Automation and Response)は、検知した脅威に対して自動で初動対応を実施するための技術です。アカウントの一時停止や通信遮断などを自動化できます。
SIEMやEDR/XDRとの連携により、「アラート検知→初動対応」までの流れを自動化し、対応スピードを大幅に向上させることが可能です。人手による初動の遅れを防ぎ、対応品質の標準化や属人化の解消にもつなげられます。
CSPM(クラウド設定の自動チェック)
CSPM(Cloud Security Posture Management)は、クラウド環境における設定不備(公開されたままのストレージ、暗号化漏れ、過剰な権限設定など)を自動で検出し、安全性を継続的に点検するための技術です。
攻撃の入口になりやすいミスを早期に発見し、侵入前に防ぐ予防的なセキュリティ対策として、SOCの精度を補完する役割を果たします。
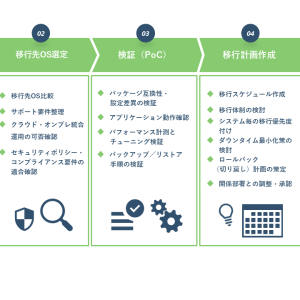
5. SOCの構築方法とポイント
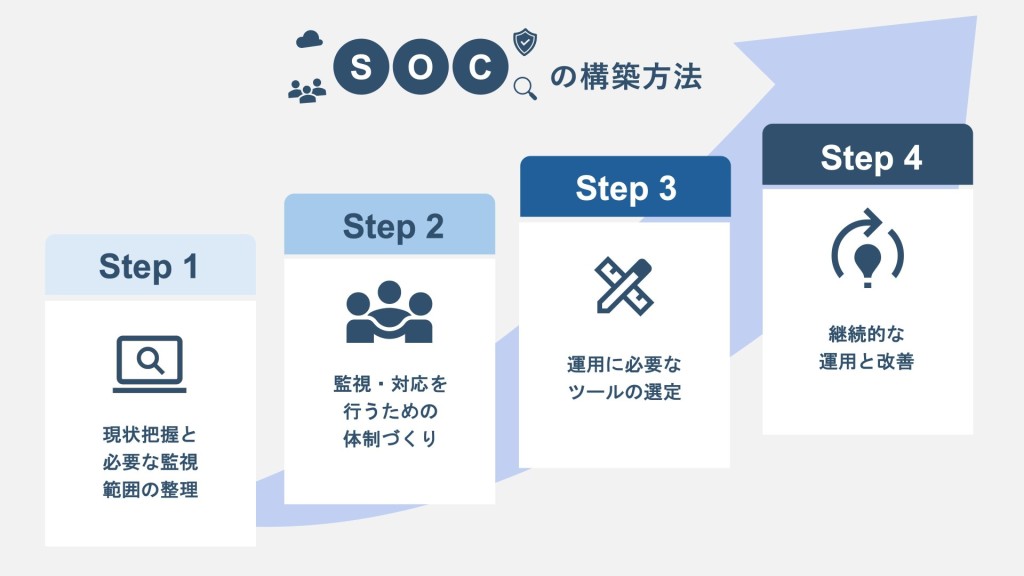
SOCを構築する際の基本的なステップを解説します。
1.現状把握と必要な監視範囲の整理
まずは自社が「何を守る必要があるのか」を明確にしましょう。対象となるシステム、データ、クラウド資産を棚卸しし、どこにどのようなリスクが存在するのかを把握します。
特にクラウド利用が進んでいる企業では、監視対象が多岐にわたるため整理することが重要です。そのうえで、既存ログの収集状況やアラート数、体制上の課題も可視化します。
2.監視・対応を行うための体制づくり
SOCは監視・分析・初動対応を常時実施する必要があり、そのためには一定の体制が求められます。担当者の確保やスキル習得への教育コストなど、運用を継続するための負担は小さくありません。
特に中堅規模の企業では、情シスが他業務を兼任しているケースが多く、十分な対応時間を確保するのが難しいこともあります。そのため、この段階で「どこまでを自社で担い、どこからを外部に委ねるか」という役割分担を検討しましょう。
3.運用に必要なツールの選定
ツール選定において重要なのは、導入することではなく、運用して成果を出せるかです。そのため、ログの収集方法やアラートの連携、他ツールとの統合など、実際の運用を想定した適切な選定が求められます。
また、アラートルールの調整やチューニングは継続的な作業であり、専門的な知識と時間が必要です。どの程度の運用負荷が発生するかを事前に把握し、自社で対応できる範囲を見極めておくことが重要です。
4.継続的な運用と改善
SOCは構築したら終わりではなく、日々の運用を継続し、改善し続けることが求められます。具体的には、インシデント対応のプロセス化、レポート作成、振り返りの実施などが必要です。
さらに、クラウド環境では構成変更が頻繁に発生するため、監視ルールや対象範囲を常に最新化しなければなりません。こうした継続的な改善を自社だけで行うのが難しい場合は、外部のSOCサービスを活用し、24時間の監視や高度な分析などを行える体制をまとめて確保することも現実的な選択肢です。
まとめ
サイバー攻撃の高度化やクラウド利用の拡大により、企業のセキュリティ監視には、従来の運用では対応しきれない課題が増えているのが現状です。そのため、24時間の継続監視・迅速なアラート分析・初動対応を一貫して行うSOCの重要性が高まっています。
しかし、複数のツール運用やルールチューニングを自社だけで回し続けることは負担が大きく、体制構築が難しい企業も多いでしょう。ハートビーツのマネージドセキュリティサービス 「SecureOps+」 では、24/365の監視から高度分析、自動隔離、復旧支援、レポート化までをワンストップで提供します。
また、ハートビーツはAWSの厳格な審査を経て得られる「MSSPコンピテンシー(Level 1 MSSP)」を保有しており、セキュリティ運用を安心して任せられる体制が整っています。「セキュリティ運用を強化したい」「常時監視体制を効率的に整えたい」という企業様は、ぜひハートビーツにご相談ください。