💦 FULL SET: Gallery - Uncensored 2025
Industrial-Strength
Natural Language
Processing
in Python
Get things done
spaCy is designed to help you do real work — to build real products, or gather real insights. The library respects your time, and tries to avoid wasting it. It's easy to install, and its API is simple and productive.
Blazing fast
spaCy excels at large-scale information extraction tasks. It's written from the ground up in carefully memory-managed Cython. If your application needs to process entire web dumps, spaCy is the library you want to be using.
Awesome ecosystem
Since its release in 2015, spaCy has become an industry standard with a huge ecosystem. Choose from a variety of plugins, integrate with your machine learning stack and build custom components and workflows.
Edit the code & try spaCy
Features
Prodigy: Radically efficient machine teaching
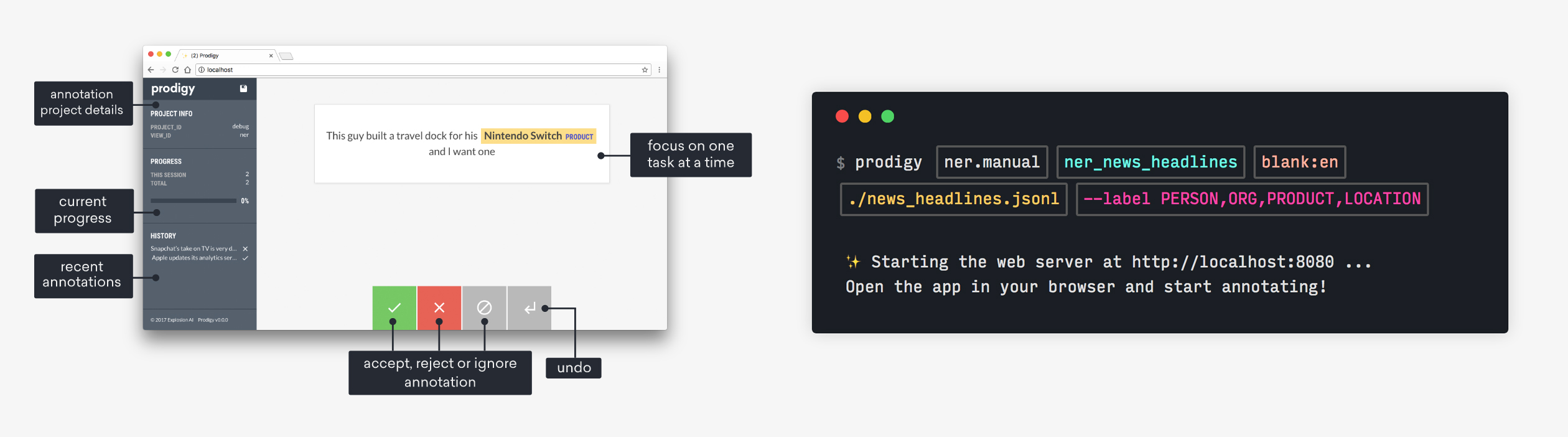
Prodigy is an annotation tool so efficient that data scientists can do the annotation themselves, enabling a new level of rapid iteration. Whether you're working on entity recognition, intent detection or image classification, Prodigy can help you train and evaluate your models faster.
Reproducible training for custom pipelines
spaCy v3.0 introduces a comprehensive and extensible system for configuring your training runs. Your configuration file will describe every detail of your training run, with no hidden defaults, making it easy to rerun your experiments and track changes. You can use the quickstart widget or the init config command to get started, or clone a project template for an end-to-end workflow.
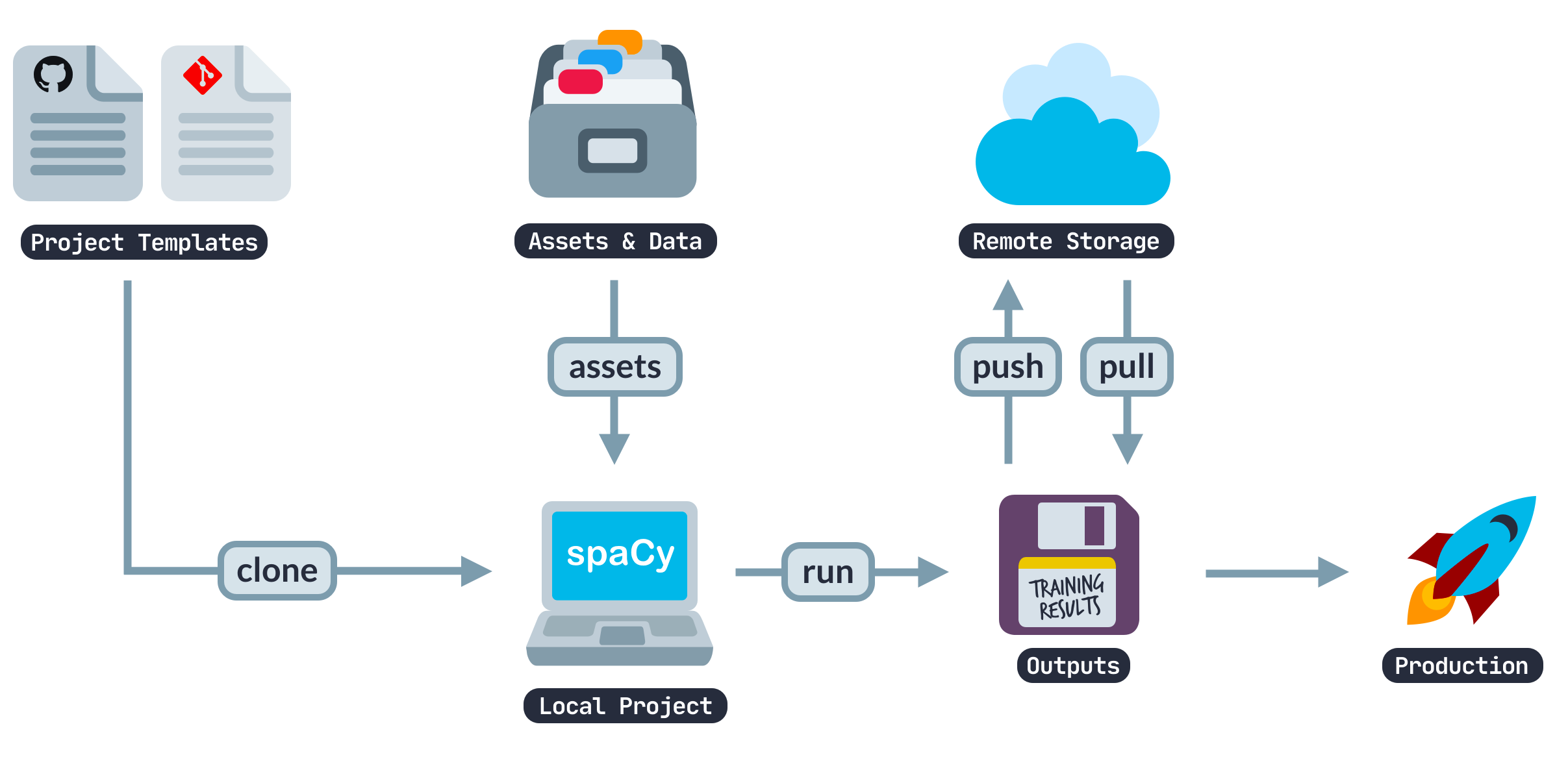
End-to-end workflows from prototype to production
spaCy's new project system gives you a smooth path from prototype to production. It lets you keep track of all those data transformation, preprocessing and training steps, so you can make sure your project is always ready to hand over for automation. It features source asset download, command execution, checksum verification, and caching with a variety of backends and integrations.

Get a custom spaCy pipeline, tailor-made for your NLP problem by spaCy's core developers.
- Streamlined. Nobody knows spaCy better than we do. Send us your pipeline requirements and we'll be ready to start producing your solution in no time at all.
- Production ready. spaCy pipelines are robust and easy to deploy. You'll get a complete spaCy project folder which is ready to
spacy project run. - Predictable. You'll know exactly what you're going to get and what it's going to cost. We quote fees up-front, let you try before you buy, and don't charge for over-runs at our end — all the risk is on us.
- Maintainable. spaCy is an industry standard, and we'll deliver your pipeline with full code, data, tests and documentation, so your team can retrain, update and extend the solution as your requirements change.
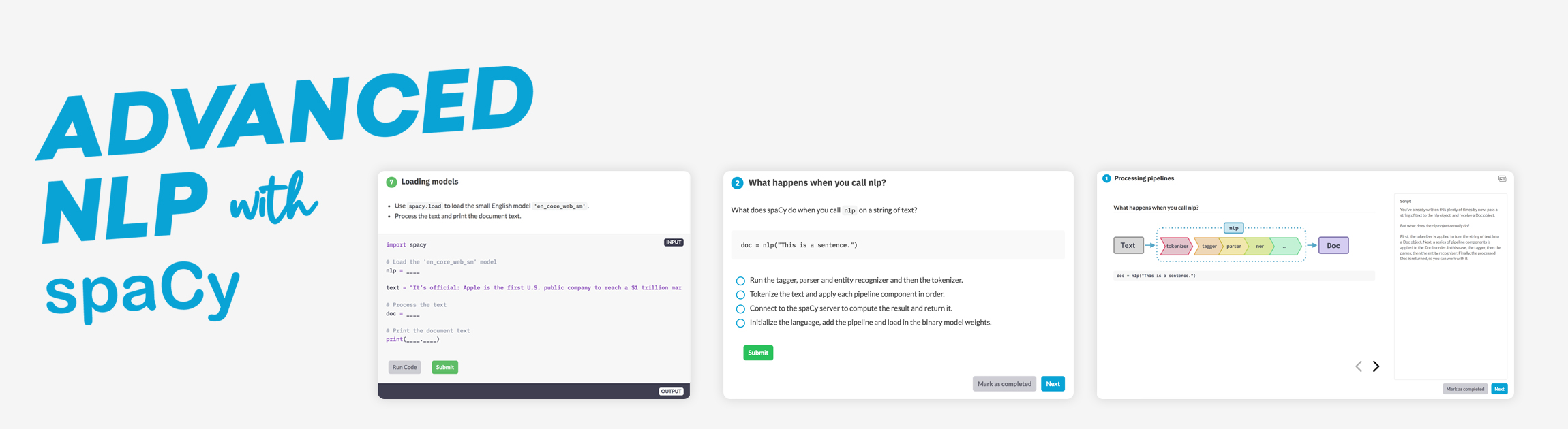
In this free and interactive online course you’ll learn how to use spaCy to build advanced natural language understanding systems, using both rule-based and machine learning approaches. It includes 55 exercises featuring videos, slide decks, multiple-choice questions and interactive coding practice in the browser.
Benchmarks
spaCy v3.0 introduces transformer-based pipelines that bring spaCy's accuracy right up to the current state-of-the-art. You can also use a CPU-optimized pipeline, which is less accurate but much cheaper to run.
| Pipeline | Parser | Tagger | NER |
|---|---|---|---|
en_core_web_trf (spaCy v3) | 95.1 | 97.8 | 89.8 |
en_core_web_lg (spaCy v3) | 92.0 | 97.4 | 85.5 |
en_core_web_lg (spaCy v2) | 91.9 | 97.2 | 85.5 |
Full pipeline accuracy on the OntoNotes 5.0 corpus (reported on the development set).
| Named Entity Recognition System | OntoNotes | CoNLL ‘03 |
|---|---|---|
| spaCy RoBERTa (2020) | 89.8 | 91.6 |
| Stanza (StanfordNLP)1 | 88.8 | 92.1 |
| Flair2 | 89.7 | 93.1 |
Named entity recognition accuracy on the
OntoNotes 5.0 and
CoNLL-2003 corpora. See
NLP-progress for
more results. Project template:
benchmarks/ner_conll03. 1.
Qi et al. (2020). 2.
Akbik et al. (2018).
